Amazon MemoryDB for Redis - Where speed meets consistency

Modern apps are not monolithic; they’re composed of a complex graph of interconnected microservices, where the response time for one component can impact the performance of the entire system. For instance, a page load on an e-commerce website may require inputs from a dozen microservices, each of which must execute quickly to render the entire page as fast as possible so you don’t lose a customer. It’s critical that the data systems that support those microservices perform rapidly and reliably, and where speed is a primary concern, Redis has always been top of mind for me.
Redis is an incredibly popular distributed data structure store. It was named the “Most Loved” database by Stack Overflow’s developer survey for the fifth year in a row for its developer-focused APIs to manipulate in-memory data structures. It’s commonly used for caching, streaming, session stores, and leaderboards, but it can be used for any application requiring remote, synchronized data structures. With all data stored in memory, most operations take only microseconds to execute. However, the speed of an in-memory system comes with a downside—in the event of a process failure, data will be lost and there’s no way to configure Redis to be both strongly consistent and highly available.
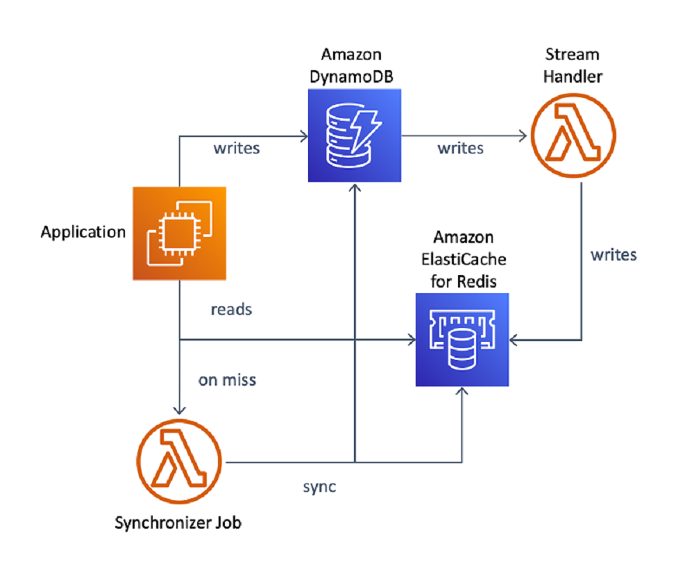
AWS already supports Redis for caching and other ephemeral use cases with Amazon ElastiCache. We’ve heard from developers that Redis is their preferred data store for very low-latency microservices applications where every microsecond matters, but that they need stronger consistency guarantees. Developers would work around this deficiency with complex architectures that re-hydrate data from a secondary database in the event of data loss. For example, a catalog microservice in an e-commerce shopping application may want to fetch item details from Redis to serve millions of page views per second. In an optimal setup, the service stores all data in Redis, but instead has to use a data pipeline to ingest catalog data into a separate database, like DynamoDB, before triggering writes to Redis through a DynamoDB stream. When the service detects that an item is missing in Redis—a sign of data loss—a separate job must reconcile Redis against DynamoDB.
This is overly complex for most, and a database-grade Redis offering would greatly reduce this undifferentiated heavy lifting. This is what motivated us to build Amazon MemoryDB for Redis, a strongly-consistent, Redis-compatible, in-memory database service for ultra-fast performance. But more on that in a minute, I’d like to first cover a little more about the inherent challenges with Redis before getting into how we solved for this with MemoryDB.
Redis’ best-effort consistency
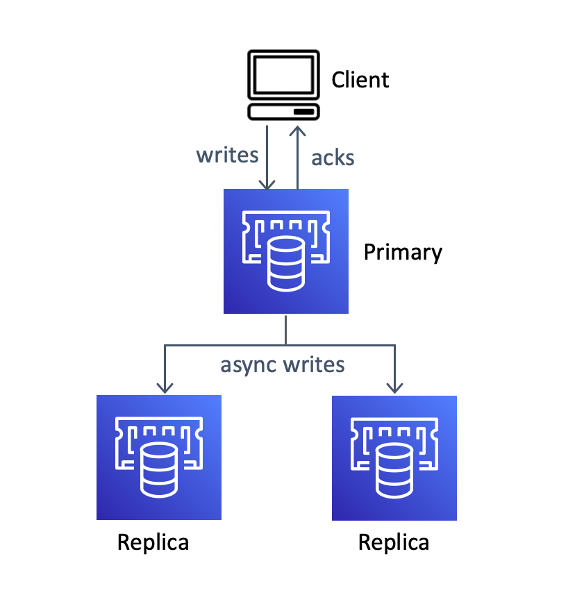
Even in a replicated or clustered setup, Redis is weakly consistent with an unbounded inconsistency window, meaning it is never guaranteed that an observer will see an updated value after a write. Why is this? Redis was designed to be incredibly fast, but made tradeoffs to improve latency at the cost of consistency. First, data is stored in memory. Any process loss (such as a power failure) means a node loses all data and requires repair from scratch, which is computationally expensive and time-consuming. One failure lowers the resilience of the entire system as the likelihood of cascading failure (and permanent data loss) becomes higher. Durability isn’t the only requirement to improve consistency. Redis’ replication system is asynchronous: all updates to primary nodes are replicated after being committed. In the event of a failure of a primary, acknowledged updates can be lost. This sequence allows Redis to respond quickly, but prevents the system from maintaining strong consistency during failures. For example, in our catalog microservice, a price update to an item may be reverted after a node failure, causing the application to advertise an outdated price. This type of inconsistency is even harder to detect than losing an entire item.
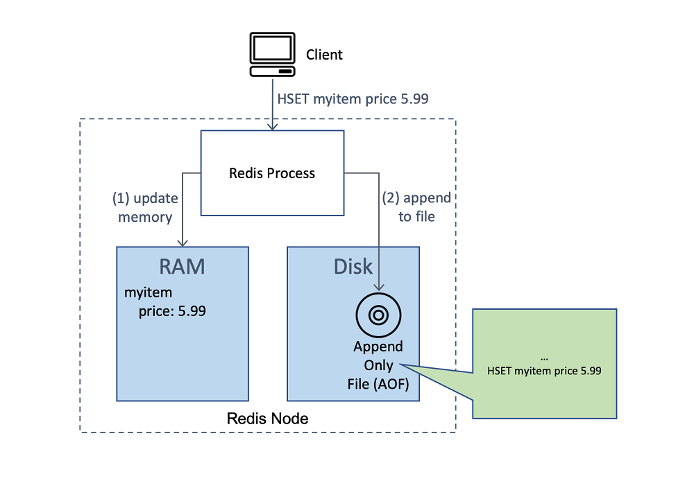
Redis has a number of mechanisms for tunable consistency, but none can guarantee strong consistency in a highly available, distributed setup. For persistence to disk, Redis supports an Append-Only-File (AOF) feature where all update commands are written to disk in a file known as a transaction log. In the event of a process restart, the engine will re-run all of these logged commands and reconstruct the data structure state. Because this recovery process takes time, AOF is primarily useful for configurations that can afford to sacrifice availability. When used with replication, data loss can occur if a failover is initiated when a primary fails instead of replaying from the AOF because of asynchronous replication.
Redis can failover to any available replica when a failure occurs. This allows it to be highly available, but also means that to avoid losing an update, all replicas must process it. To ensure this, some customers use a command called WAIT, which can block the calling client until all replicas have acknowledged an update. This technique also does not turn Redis into a strongly consistent system. First, it allows reads to data not yet fully committed by the cluster (a “dirty read”). For example, an order in our retail shopping application may show as being successfully placed even though it could still be lost. Second, writes will fail when any node fails, reducing availability significantly. These caveats are nonstarters for an enterprise-grade database.
MemoryDB: It’s all about the replication log
We built MemoryDB to provide both strong consistency and high availability so customers can use it as a robust primary database. We knew it had to be fully compatible with Redis so customers who already leverage Redis data structures and commands can continue to use them. Like we did with Amazon Aurora, we started designing MemoryDB by decomposing the stack into multiple layers. First, we selected Redis as an in-memory execution engine for performance and compatibility. Reads and writes in MemoryDB still access Redis’ in-memory data structures. Then, we built a brand new on-disk storage and replication system to solve the deficiencies in Redis. This system uses a distributed transaction log to control both durability and replication. We offloaded this log from the in-memory cluster so it scales independently. Clusters with fewer nodes benefit from the same durability and consistency properties as larger clusters.
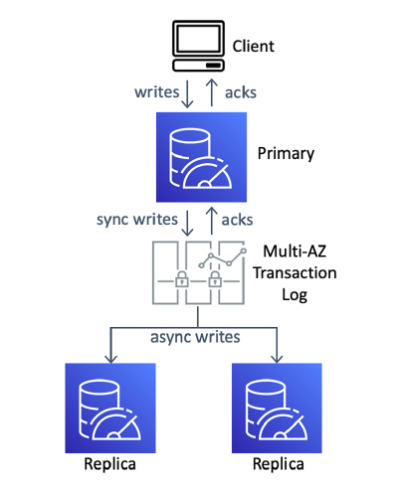
The distributed transaction log supports strongly consistent append operations and stores data encrypted in multiple Availability Zones (AZs) for both durability and availability. Every write to Redis is stored on disk in multiple AZs before it becomes visible to a client. This transaction log is then used as a replication bus: the primary node records its updates to the log, and then replicas consume them. This enables replicas to have an eventually consistent view of the data on the primary, providing Redis-compatible access methods.
With a durable transaction log in place, we shifted focus to consistency and high availability. MemoryDB supports lossless failover. We do this by coordinating failover activities using the same transaction log that keeps track of update commands. A replica in steady-state is eventually consistent, but will become strongly consistent during promotion to primary. It must append to the transaction log to failover and is therefore guaranteed to observe all prior committed writes. Before accepting client commands as primary, it applies unobserved changes, which allows the system to provide linearizable consistency for both reads and writes across failovers. This coordination also ensures that there is a single primary, preventing “split brain” problems typical in other database systems under certain networking partitions, where writes can be mistakenly accepted simultaneously by two nodes only to be later thrown away.
Redis-compatible
We leveraged Redis as an in-memory execution system within MemoryDB, and needed to capture update commands on a Redis primary to store them in the transaction log. A common pattern is to intercept requests prior to execution, store them in the transaction log, and once committed, allow nodes to execute them from the log. This is called active replication and is often used with consensus algorithms like Paxos or Raft. In active replication, commands in the log must apply deterministically on all nodes, or different nodes may end up with different results. Redis, however, has many sources of nondeterminism, such as a command to remove a random element from a set, or to execute arbitrary scripts. An order microservice may only allow orders for a new product to be placed after a launch day. It can do this using a LUA script, which rejects orders when submitted too early based on Redis' clock. If this script were run on various replicas during replication, some nodes may accept the order based on their local clock and some may not, causing divergence. MemoryDB instead relies on passive replication, where a single primary executes a command and replicates its resulting effects, making them deterministic. In this example, the primary executes the LUA script, decides whether or not to accept the order, and then replicates its decision to the remaining replicas. This technique allows MemoryDB to support the entire Redis command set.
With passive replication, a Redis primary node executes writes and updates in-memory state before a command is durably committed to the transaction log. The primary may decide to accept an order, but it could still fail until committed to the transaction log, so this change must remain invisible until the transaction log accepts it. Relying on key-level locking to prevent access to the item during this time would limit overall concurrency and increase latency. Instead, in MemoryDB we continue executing and buffering responses, but delay these responses from being sent to clients until the dependent data is fully committed. If the order microservice submits two consecutive commands to place an order and then retrieve the order status, it would expect the second command to return a valid order status. MemoryDB will process both commands upon receipt, executing on the most up-to-date data, but will delay sending both responses until the transaction log has confirmed the write. This allows the primary node to achieve linearizable consistency without sacrificing throughput.
We offloaded one additional responsibility from the core execution engine: snapshotting. A durable transaction log of all updates to the database continues to grow over time, prolonging restore time when a node fails and needs to be repaired. An empty node would need to replay all the transactions since the database was created. From time to time, we compact this log to allow the restore process to complete quickly. In MemoryDB, we built a system to compact the log by generating a snapshot offline. By removing snapshot responsibilities from the running cluster, more RAM is dedicated to customer data storage and performance will be consistent.
Purpose-built database for speed
The world moves faster and faster every day, which means data, and the systems that support that data, have to move even faster still. Now, when customers need an ultra-fast, durable database to process and store real-time data, they no longer have to risk data loss. With Amazon MemoryDB for Redis, AWS finally offers strong consistency for Redis so customers can focus on what they want to build for the future.
MemoryDB for Redis can be used as a system of record that synchronously persists every write request to disk across multiple AZs for strong consistency and high availability. With this architecture, write latencies become single-digit milliseconds instead of microseconds, but reads are served from local memory for sub-millisecond performance. MemoryDB is a drop-in replacement for any Redis workload and supports the same data structures and commands as open source Redis. Customers can choose to execute strongly consistent commands against primary nodes or eventually consistent commands against replicas. I encourage customers looking for a strongly consistent, durable Redis offering to consider Amazon MemoryDB for Redis, whereas customers who are looking for sub-millisecond performance on both writes and reads with ephemeral workloads should consider Amazon ElastiCache for Redis.
To learn more, visit the Amazon MemoryDB documentation. If you have any questions, you can contact the team directly at memorydb-help@amazon.com.