Continuous Configuration at the Speed of Sound

One of the many things I have missed since the start of the COVID-19 pandemic is the thrill of seeing live music. Nothing beats feeling, hearing, and seeing music performed live. It's the real-time interaction between the audience and the performer that elevates great music into something euphoric. Whatever the genre, as a performer, it takes years of skill and experience to know how to deliver memorable and unique live performances.
As music venues begin to open again, I was able to recently watch Joyce DiDonato perform at The Royal Concertgebouw here in Amsterdam. She was accompanied by pianist Craig Terry. Like most of my experiences these days, I couldn’t help but think about the concert through the lens of a developer.
As a team, DiDonato and Terry adjusted elements of their performance throughout the set. The sheet music was a sound starting point, but by adding small improvisations and flourishes, extending solos, and altering tempo in response to the crowd’s feedback, the pair used these changes to elevate their performance, creating moments that will live on in the memories of their audience for years to come.
As builders, we can learn something from performers and live events like this. Authoring performant, error-free code is a necessary first step, but applications should be thought of as dynamic and living things that can adapt and react in real-time to events such as service failures, peaks in demand, and changes to steady state. The key to achieving this level of adaptability is making it easy and safe to change configuration on the fly, so that adjusting an application's behavior is as easy as pressing a button.
Amazon.com is an excellent example of a system that does this well. Prime Day is a major, live event that brings about scale and throughput challenges that require a dynamic technology stack that can react in real time to meet customer demand. But unlike the DiDonato and Terry concert duo, adjusting the systems that power an event like Prime Day in real time is something that requires coordination and input from thousands of developers across hundreds of internal organizations within Amazon.
The old way of doing things
In the early days of Amazon.com, making changes to the ecommerce codebase was complex, slow, and fraught with danger. A single change would require a complete re-deploy of a single monolithic executable. That executable was over a gigabyte in size and took over a day to compile. There was so much time between making a change in the codebase and seeing the impact in production that it was difficult to correlate the two. Over the years, as Amazon scaled and grew, this slow software deployment process was a bottleneck that limited the pace at which we could deliver features and application improvements for our customers. To solve this, we broke down the monolith, moving towards a service-oriented design. This empowered teams to ship features faster and more frequently and reduced the blast radius of changes to individual services. With this shift of ownership came the need for individual teams to manage the deployment and operation of their services, resulting in the creation of many streamlined processes and procedures similar to the CI/CD pipelines we use today.
At this point, configuration was still managed directly within an application’s codebase, making changes slow and still requiring a service to be redeployed or restarted to adopt a new configuration. It was clear that while CI/CD practices and technologies solved for many of the deployment challenges, there was still a lack of ability to modify application behavior quickly, especially in response to dynamic live environments. That capability is necessary to achieve the availability requirements for a system like Amazon.com.
We realized that code release is only the beginning, and that we needed to develop three capabilities if we wanted to move faster:
The ability to store and update configuration data quickly, separate from code deployment;
The ability to have applications fetch configuration from an external service;
The ability to check and validate configurations for safety.
To achieve these objectives, we began building a centralized dynamic configuration management system that could enable teams across Amazon to store and fetch application configurations quickly and reliably. This system enabled teams at Amazon to separate configuration values from application code and respond to configuration updates as they changed, removing the need for lengthy redeploys and application restarts to alter behavior.
The process by which configuration is managed separately from application code and continuously queried at runtime, which we call continuous configuration (CC), has had a fundamental impact on our ability to maintain high levels of availability while being able to adapt and react in real time. As the centralized system and CC process became more well-known within Amazon, teams began using it to build all kinds of large-scale systems, including AWS. In 2019, we announced AWS AppConfig as a capability within AWS Systems Manager so that customers could benefit from the same lessons we learned while implementing their own continuous configuration practices.
CC. Yet another acronym?
Just as Amazon evolved, external developers have been using application configuration to change how their software behaves for a very long time. But generally, this configuration is static in nature and companies remain stuck using antiquated techniques that don’t allow them to best serve their customers. The configuration is loaded as an application initializes and then remains the same until the app restarts. Alternatively, some customers have hacked together ways to pull these configuration details from other places, be it Amazon S3 or a database entry somewhere. And while this can work for some, these custom solution implementations often face constraints around latency, scalability, ease of use, and more.
True dynamic configuration is different. The source of configuration truth lives in an independent configuration management system, and is polled by the consuming application(s). These are configuration values that an engineer anticipates will need to be changed easily in the future or might vary according to specific system conditions, even if they don’t know exactly when that will be. These values often fall into two groups: those that modify operational behavior of an application—such as throttling, limits, connection limits, or logging verbosity—and those that control FAC (Feature Access Control), including feature flags, A/B testing, and user allow/deny lists.
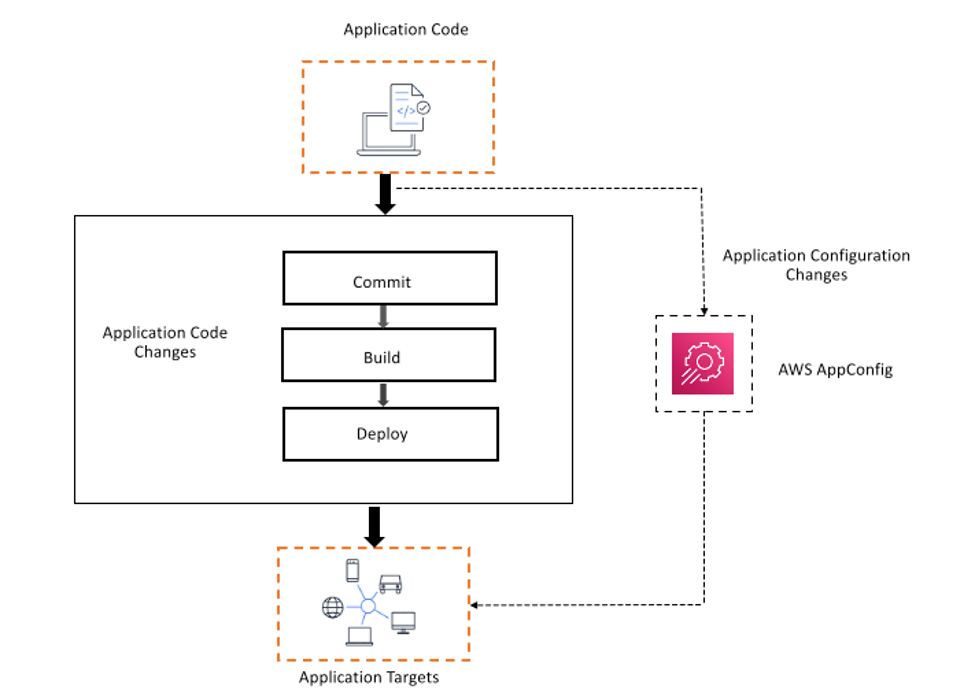
Continuous configuration is the process of updating these dynamic configuration values during runtime, all without deploying new code or restarting the app. It's also the practice of rolling out those changes in a controlled way using a deployment strategy across your application fleet.
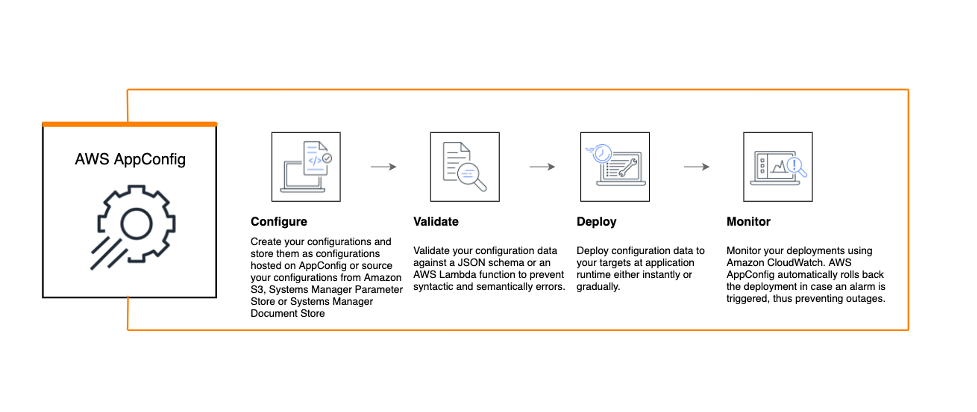
Through building AppConfig, we learned a lot about how to do continuous configuration well and how to avoid some of the problems that it may introduce. For example, you need to be able to deploy configuration changes without compromising application availability. Therefore, AppConfig can validate configuration data to ensure that it is both syntactically and semantically correct. This means that an accidental invalid or incomplete data entry doesn’t have disastrous effect, such as rendering the application unavailable.
There are other fallback mechanisms to ensure that a mistake doesn't snowball into a disaster. For example, AWS AppConfig allows you to deploy the configuration changes to only a small percentage of users to analyze the effects of the configuration changes before rolling them out, so you can limit the blast radius in case of an issue. We have also built a mechanism for teams to be alerted if a deployment did not proceed as expected and easily roll back to a previous version.
Feature Access Control
Feature flags are a common use case for continuous configuration. They allow developers to release new end-user capabilities nearly instantly without requiring the operational risk and time cost of a full application redeploy.
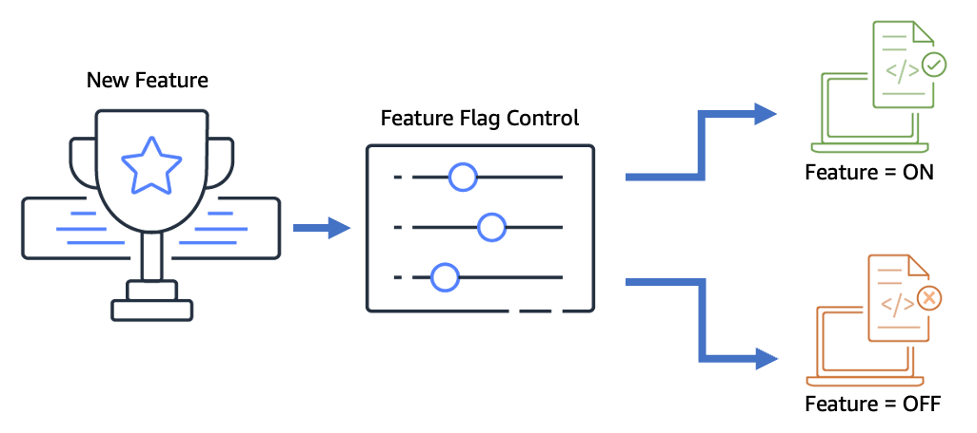
A common use-case for this capability is in delivering an application change for an event occurring at a precise time, where a configuration change in a CC system is much smaller, quicker, and more reliable than trying to re-launch an entire application or rely on a DNS switchover. As an example, a customer who produces a TV show could use AppConfig to manage audience participation, so that voting user interfaces can be displayed inside of mobile applications at the very moment that the TV host announces that "voting is now open" on the latest reality show and closed for all users as soon as the period has completed.
At AWS, we use AppConfig when we launch services. When a new service is in development, it will often be in production before it’s released, and internal users and some partners are granted access to provide feedback or produce launch materials. We add these users via an allowlist managed by a continuous configuration system. When the service launches, such as following an announcement at re:Invent, we change the configuration so the service is available to all accounts and not just those on the allowlist. As new features enter preview, it is significantly easier to manage a single production deployment with an allowlist for beta users, compared to managing a separate stable beta build of the application concurrently.
You might be thinking that these use cases could simply use database switches or some in-memory flag to solve this problem, but in our experience, writing configuration systems is complicated, particularly at scale. One of the things we’ve learned analyzing internal Correction of Errors (COE) over the last few years is that configuration changes cause outages at about the same rate as code changes. And when it comes to resolving outages, manual configuration changes are being made when stress levels are high, further increasing the risk of errors in changes or attempted rollbacks. In the moment where changes are most critical, validation systems and guard rails help give you surgical precision when your hand is normally the shakiest.
Looking Forward
In much the way that CI/CD reduced the fear of deployment, continuous configuration reduces the fear of changing configuration. By exercising this capability regularly, we build confidence and can start to enable automation. AppConfig builds in this automation. For example, if you create a CloudWatch Alarm that performs a health check into your application, you can have AppConfig monitor the alarm. Then, during the deployment of a configuration change, if the CloudWatch Alarm goes into an alarm state, the deployment will roll back.
I think this is where continuous configuration starts to change the way we can operate. By making it easier and safer to change the configuration, we are democratizing configuration. A nonobvious benefit of continuous configuration systems like AppConfig is that they can provide the right protective guardrails to enable a broader set of product stakeholders to self-serve changes in application behavior. From a junior engineer looking to scale up the number of database connections, to a product manager that wants to add a customer to beta service access, to a UX designer that wants to modify an A/B test’s experimental cohort split, the democratization of service ownership helps to remove operational engineers as a bottleneck for all changes to a production application.
Or, perhaps we’re able to safely give certain dials and switches to business intelligence or data science teams and enable them to make real-time configuration changes. It’s interesting to imagine the kinds of new ideas and innovations that become possible when we enable this— systems that not only react to events and alarms, but can instead predict when you might need to switch to a different configuration.
Live in the Moment
In business, as in music, speed, and timing matter, and success is where opportunity meets capability. For performers like DiDonato, timing is everything. If she misreads the audience or if the pianist is incapable of making the improvisation he wants when he wants, then the flow is destroyed and the connection with the audience is lost. For your business, when an opportunity arises, your applications must have the ability to adapt in an instant. If you can't, well, your competitors might.
By using continuous configuration to react to changes in real-time, you are building your capability so that when an opportunity presents itself, you will be able to respond. And, who knows? In the future, we might be able to respond to events before they have even happened.