Happy 15th Birthday Amazon S3 -- the service that started it all

15 years is a long time in the world of technology. Back when S3 launched on March 14, 2006 (also known as “Pi Day” to some), iPhones didn’t exist, neither did tweets or likes, Facebook was still only used by a few colleges and universities, and you couldn’t hail a ride or order lunch with an app.
Back then, Amazon was ~2% of its size today, and was growing faster than traditional IT systems could support. We had to rethink everything previously known about building scalable systems. Storage was one of our biggest pain points, and the traditional systems we used just weren’t fitting the needs of the Amazon.com retail business.
When we took a hard look at our storage for the Amazon ecommerce web site in 2005, we realized that the majority of our data needed an object (or key-value) store. We had images for products sold on Amazon.com, video files, etc., and we needed the low cost with high reliability that wasn’t readily available in storage solutions. At the time, the universe of data storage lived in blocks and files. Object storage platforms existed, but they wouldn’t scale to fit our ambitions. As we laid it out in the original S3 press release, we needed a storage service that met the following design criteria:
Scalable: Amazon S3 can scale in terms of storage, request rate, and users to support an unlimited number of web-scale applications. It uses scale as an advantage: adding nodes to the system increases, not decreases, its availability, speed, throughput, capacity, and robustness.
Reliable: Store data durably, with 99.99% availability. There can be no single points of failure. All failures must be tolerated or repaired by the system without any downtime.
Fast: Amazon S3 must be fast enough to support high-performance applications. Server-side latency must be insignificant relative to Internet latency. Any performance bottlenecks can be fixed by simply adding nodes to the system.
Inexpensive: Amazon S3 is built from inexpensive commodity hardware components. As a result, frequent node failure is the norm and must not affect the overall system. It must be hardware-agnostic, so that savings can be captured as Amazon continues to drive down infrastructure costs.
Simple: Building highly scalable, reliable, fast, and inexpensive storage is difficult. Doing so in a way that makes it easy to use for any application anywhere is more difficult. Amazon S3 must do both.
Eleven nines
You’ve hopefully heard us talk about a culture of durability by now. Mai-Lan Tomsen Bukovec, who is the VP responsible for S3 and EBS, talked about durability extensively at re:Invent 2019. From the beginning, S3 has been built around a culture of durability. And pretty soon after we launched S3, we framed up our design for durability as 99.999999999% (11 9s). For context, customers operating on-premises typically store two copies of their data in the same data center, giving them 99.99% durability. Exceptional customers sometimes have two data centers and they replicate data between them to get 99.999% durability.
Data is so critical to our businesses these days that data loss is just not tolerable. We replicate data across multiple different disks in different racks throughout a single data center to protect against disk-level, or even rack-level, hardware failures or networking failures within the data center. We use our replication model across a minimum of 3 Availability Zones, which are separate data centers (sometimes more than one) on different campuses, typically separated by kilometers. This protects against site-level failures, all the way up to the destruction an entire Availability Zone. We also have microservices that continually go around and perform cyclic redundancy checks (CRCs) that detect things like bit rot and bit flips and initiate the necessary repairs.
So, we took a lot of steps to protect that data against loss due to infrastructure concerns, but we also know that software introduces another level of complexity in delivering durability. So, we are now using automated reasoning by employing formal logic to validate the correctness of algorithms used in durability critical aspects of S3. With all of these elements combined, we are confident that customer data stored in S3 is many orders of magnitude more durable than data stored in advanced on-premises enterprise infrastructure.
Delivering simple, automated solutions to solve hard problems
We knew a couple of things when we launched S3: 1/we knew we had no idea of all of the ways that customers were going to use the service, and 2/we knew that the way software was being developed was changing radically. Because of this, we wanted to keep things as simple as possible, and then build on the functionality that our customers told us they needed. This allowed us to focus on the most important functionality, and then build additional functionality in as customers told us how they wanted to use S3.
This continuous pattern of customer engagement and product innovation over the last 15 years has made S3 simpler to manage at scale, more performant, lower cost, and more secure. It’s also set the precedent for how we’ve built all other cloud services since then. We’ve been highlighting a number of our past launches as we celebrated S3’s birthday over the course of AWS Pi Week, including S3 Lifecycle management, Access Points, and Storage Lens, but here I want to focus on two launches in particular and how they came to fruition. The launches of S3 Intelligent-Tiering and S3 Replication Time Control are exactly the types of fully managed, simple, and ground-breaking features you can launch when you’re not afraid to take on big challenges and when you truly listen to your customers.
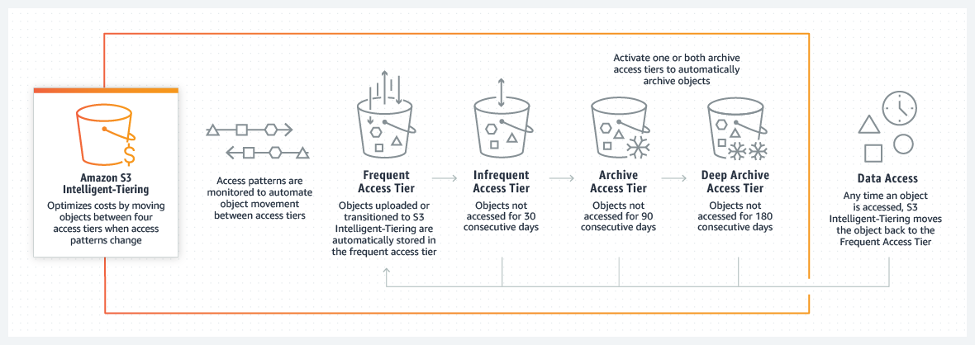
Prior to creating S3 Intelligent-Tiering, we spent a lot of time with customers discussing data management, how they monitored access patterns, and how more and more applications were starting to access shared data lakes. We learned a lot from these customers about their desire to cost optimize, the challenges of monitoring objects at scale with custom-built tooling, and the need for predictability when access patterns do change. We knew we really needed a complete solution that could optimize data automatically. That’s how we came to build a storage class that solved these needs for our customers. S3 Intelligent-Tiering, an S3 storage class launched in 2018, is designed for customers who want to optimize storage costs automatically when data access patterns change, without performance impact or operational overhead. S3 Intelligent-Tiering is the first cloud object storage class that delivers automatic cost savings by moving data between two access tiers—frequent access and infrequent access—when access patterns change, and is ideal for data with unknown or changing access patterns. More recently, in November 2020, we added an Archive and a Deep Archive Tier to S3 Intelligent-Tiering so customers can save even more on rarely access data. The heart of Intelligent-Tiering is simplicity. The storage class itself provides dynamic pricing based on individual object access. That concept of simple experience with deep engineering behind it was true about S3 in 2006, and it’s true today.
The launch of S3 Replication Time Control (RTC) is another great example. S3 Replication is a fully managed, low-cost feature that automatically replicates objects between buckets. Under the hood, RTC solves very complex infrastructure challenge (automatically replicating any volume of data between any two regions within a time window of 15 minutes or less), and customers can turn on the capability with a single click in the console or API call – with an AWS SLA.
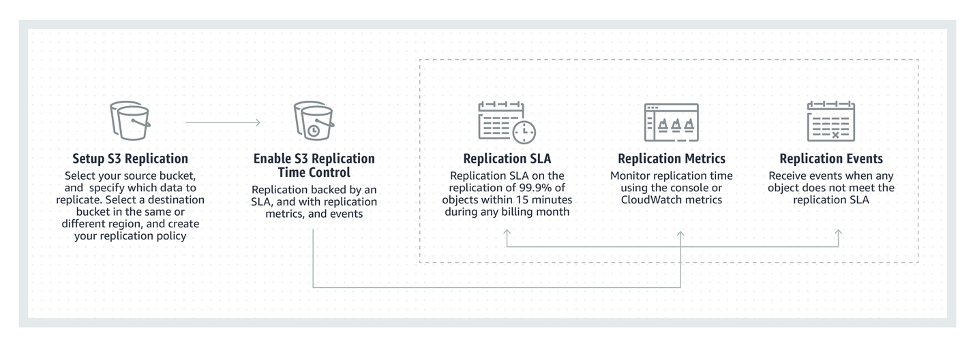
No other storage provider offers an SLA on storage replication between regions. S3 built the system and offers the SLA because they learned how important predictable replication is for Tier 1 business critical workloads. Customers didn’t want to build their own data transfer and monitoring tools. So, the S3 team dug into automatically managing bandwidth capacity for individual customers, tracking progress on replication, and other technical challenges. Like so many other S3 features, S3 Replication Time Control, launched in 2019, is the culmination of deep, technical investment but to our customers is simple to activate, easy to monitor, and has usage-based pricing. Under the hood, there’s a set of complex systems that are managing the reporting and auditing to track progress for all outstanding replication tasks for accurate calculation of per-customer recovery points. We had to build the infrastructure and automated control plane to manage bandwidth allocation and capacity planning. We also spent a lot of time designing to provide strong performance isolation and prioritization so we can gracefully handle unexpected traffic surges. And we had to do it all at the massive scale of S3. That’s what goes into the engineering of S3 – start with a simple customer experience, and engineer it at scale.
Data is at the center of everything
As analytics, machine learning, and artificial intelligence have grown into the mainstream, S3 has been at the center of all of it. By aggregating more data into a single location and experimenting with a number of different tools and technologies, customers learn that they can do things in AWS that were impossible on their old infrastructure. S3 helps customers turn their data into their crown jewels. They’ve even recognized that analytics of “mundane” data, like logs, can drive better recommendations and better decision making that makes their organizations more productive. It allows customers like iRobot to proactively identify maintenance issues in their robots, FINRA to replay the entire stock market to identify illegal trading activity, and Georgia-Pacific to save millions of dollars by optimizing their manufacturing processes. It helps companies like Moderna accelerate development of a COVID-19 vaccine and GE Healthcare connect healthcare providers for better collaboration and patient care. It all comes down to their confidence that their data is more secure, durable, and available in S3 than it is anywhere else, and that they know that they’ll be able to innovate faster to deliver value to their customers that grows their usage.
Technology is changing faster than ever before, and services like S3 have allowed so many technologists to put all of their energy into their big ideas and stop focusing on managing storage. In fact, I find S3 so remarkable that over the next few weeks and months, I’m going to spend some time going deeper into some of the areas that make S3 so special, such as our approach to durability and security. We’ll also talk a little bit more about the new S3 Object Lambda feature that we just announced. Stay tuned for more here.
So, here’s to the next 15 years of Amazon S3 and how it’s helping customers change the world, one dataset at a time!