How the Seahawks are using a data lake to improve their game

Growing up in the Netherlands, American football was largely a foreign concept to me. My version of football was The Beautiful Game, or as most Americans know it, soccer. Football, futbol, soccer, or whatever else you call it, will always be something I’m deeply passionate about, especially my hometown team, Ajax.
When I joined Amazon and Seattle became my new home, I began to see how my colleagues shared this same level of passion for American football – and particularly the fervent fans known as “The 12s” of the local team, the Seattle Seahawks. As I started to better understand this version of football, it was easy for me to get excited about the game as well as what was happening behind the scenes. Coaching staffs, decision makers, and even the announcers are using data to make real-time decisions, each team constantly working to gain even a fraction of an advantage over its opponent.
One of the things that I find most interesting about football is how the evolution of technology is having an impact on its progression. In my opinion, the Seahawks are one of the best examples of this, where they have been at the forefront in adopting new technology, like machine learning (ML), Internet of Things (IoT), and serverless architecture, to make improvements from player safety to performance on the field.
But all of these technologies start with data. That’s why last year the Seahawks selected AWS as its official cloud partner and have worked with AWS to build a data lake, a centralized repository that allows organizations to store, govern, discover, and share all of their structured and unstructured data at any scale.
The Seahawks adopted a serverless architecture, with solutions like Amazon S3, AWS Lambda, AWS Fargate, AWS Step Functions, and AWS Glue, to build their data lake and ingestion pipeline. Their data originates from a variety of on-premises and third party data sources, such as NFL Next Gen Stats (powered by AWS), Pro Football Focus (also powered by AWS), player telemetry data from IoT sensors, and tagged plays based on third-party applications.
With this data lake, the Seahawks hope to improve talent evaluation and acquisition, player health and recovery times, and game planning. Let’s look a little closer at these three areas, how technology can fuel improvements, and the architecture behind the Seahawks’ data lake.
Talent evaluation and acquisition
Historically, football teams evaluated potential players by having scouts go to as many games as possible and poring over videotape. Obviously, this approach has limitations – for example, the evaluation might not be objective, and it’s very time consuming.
That’s why the Seahawks supplement traditional scouting with AWS analytics for player evaluation. First they collect data about the player, like the size of the school the player comes from, the position they play, and the roles they’ve played within that college team’s style of play. Then they take data about the Seahawks, like their own style of play, the current players on the team, and more, and use an ML model to evaluate whether or not the player is a good fit.
During the draft, the Seahawks might have ranked a player higher than other teams using this analysis, allowing them to trade down during the draft and still select the right player for the team while acquiring more draft picks. This type of modeling has also helped during free agency where the Seahawks have signed a player that creates the most value for the team, in turn making the biggest impact without over-spending against the NFL’s salary cap.
In addition to having the right data to make these important decisions, the Seahawks have a dashboard that makes the information easy to understand and take action on. Figure 1 gives an example of the kind of analytics dashboard used by the Seahawks in preparation for the 2020 draft.
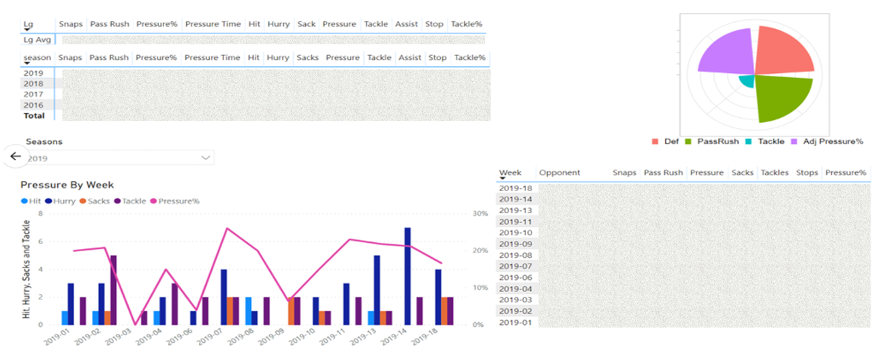
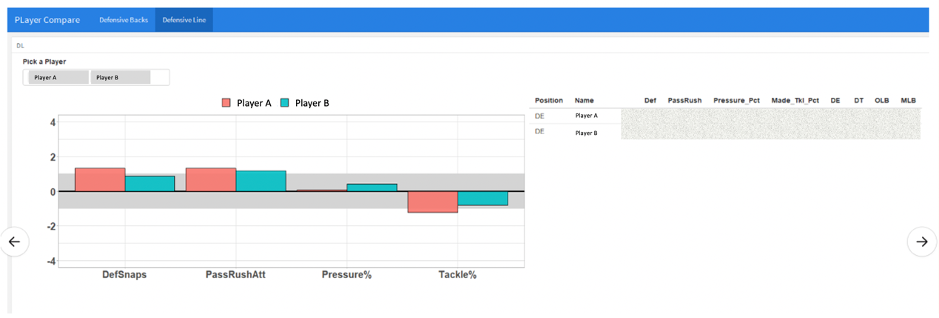 Figure 1: Seahawks 2020 draft data snapshot
Figure 1: Seahawks 2020 draft data snapshot
Player health and recovery times
Nothing is more important to the Seahawks than the health and safety of their players. That’s why they invest heavily in medical staff, strength and conditioning training, and nutrition for everyone on the team. And data plays a critical role in making decisions related to player health, too.
Each player receives an initial baseline health assessment. Then the Seahawks collect ongoing information about players, like their exertion level, their trend of reps in practice, their explosive movements, how often they work out, and more. Tracking this data allows the Seahawks to maximize a player’s gains, reduce soft tissue injuries, and better understand their load from practice to games. They also use this data to develop unique training plans that will optimize the athletic talents of the different players, help players reach their goals, and get the most out of their performance.
Previously, the Seahawks had this data sitting in segmented data buckets, making it difficult to parse the information. It was difficult to get a complete view of a player’s health. Now, with their data lake on AWS, this information is easily accessible, all in one place. What is more, the Seahawks can get a real-time assessment of a player’s wellbeing, helping them to make informed decisions, like before an injury occurs.
Game planning
Game day is what football fans live for. But what most people don’t realize is that it takes a sports organization hundreds of hours to ready a team for its 60 minutes on the field every week. One task in particular that’s vital to the game planning process is video analysis.
Every team records its practices during the week and then works to break it down during film room sessions. The Seahawks have worked with the Amazon Machine Learning Solutions Lab to build custom ML models that automatically identify players on the field and the type of play. Using these ML models, the Seahawks plan to automate many of the manual processes in video analysis.
This type of video analysis can also be broken down by player. Thinking back to the talent acquisition, the Seahawks data scientists can load plays from a player’s career and see what they’ve been most successful doing, which could help integrate that player into certain schemes and maximize their results faster than before. For example, by viewing traits of a player it might show that he would be a great performer even when put into a position he may not have a lot of experience in.
What’s really cool is how the Seahawks organization can all pull from the same data lake for lots of different purposes. And the team is really tapping into so many various services and functions within AWS—from machine learning, to artificial intelligence, to databases, analytics, storage, and more.
The Seahawks data lake architecture
In thinking through the use cases above, it’s easy to see how a data lake was the right technology solution here. And AWS offers numerous services and technologies that are ideal for building a data lake in the cloud.
 *Figure 2: Seahawks Data Lake Architechture*
*Figure 2: Seahawks Data Lake Architechture*An AWS Lambda function initiates the ingestion of data on a pre-defined schedule by starting AWS Step Functions. The Step Functions orchestrates the ingestion workflow from start to finish by managing state, checkpoints, and retries to make sure that ingestion process executes in order and as expected.
As part of this workflow, AWS Step Functions spins up independent docker images on AWS Fargate to query the third party source API and copy the data into a S3 bucket. Fargate allocates the right amount of compute for each container, eliminating the need to choose instances and scale cluster capacity manually. Because Fargate is serverless, it allows the Seahawks to avoid the operational overhead of scaling, patching, securing, and managing servers.
After the data is ingested into the S3 bucket, Amazon Glue crawls the data and constructs a Data Catalog using pre-built classifiers. By maintaining an up-to-date data catalog on Glue, the Seahawks can quickly discover and search across multiple AWS data sets without moving the data.
 *Figure 3: Data Ingestion Pipeline for 3rd Party APIs*
*Figure 3: Data Ingestion Pipeline for 3rd Party APIs*In addition to third party APIs, the Seahawks need to ingest data from on-premises relational databases and data warehouses. AWS Database Migration Services allows them to easily and securely pull data out of a variety of source databases and data warehouses and land into S3 before loading it to Amazon Redshift. This allows the data to be available in the data lake for ML and other use cases while ensuring data that is intended for analytics queries can be loaded efficiently to Amazon Redshift.
 *Figure 4: Data Ingestion Pipeline for on-premises data sources*
*Figure 4: Data Ingestion Pipeline for on-premises data sources*If there is any failure in the ingestion workflow, the underlying API call will be logged to AWS CloudWatch Logs. Then, AWS Step Functions will notify the Seahawks data analytics team about the failure via email using Amazon Simple Notification Service.
Putting it all together
Since announcing that AWS is the Seahawks official cloud provider last year, the Seahawks data lake has been operational for seven months now, and they’re already seeing value in its talent evaluation and acquisition, player health and recovery times, and game planning.
While American Football is one of the most exciting and most physical sports I’ve ever seen, what continues to impress me with this sport every year is the insights, data, and technology that plays into the sport these days. A successful football franchise like the Seattle Seahawks not only need MVP candidates like Russell Wilson on the field, but a strong team of technologists and some of the best technologies on the planet working together behind the scenes to win in a league like this. And the performance of the Seahawks this season – 6-3 and tied for first place in the NFC West – has been aided by all of the meticulous preparation put into every game day, some of which is coming directly from this data lake. I know it takes a lot of people throughout a football organization to get a team to the Super Bowl, and AWS is proud to play a small role in the Seahawks success, now and in the future.