Weekend Reading: Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases.
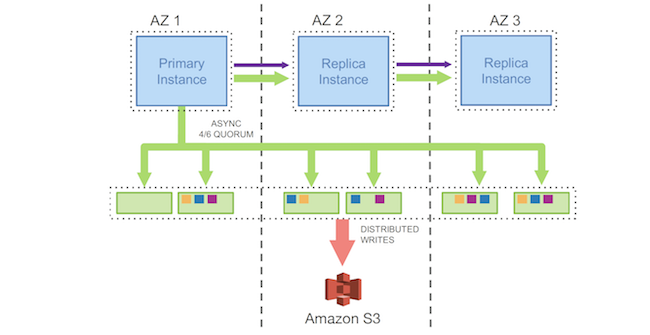
In many high-throughput OLTP style applications, the database plays a crucial role in achieving scale, reliability, high-performance, and cost efficiency. For a long time, these requirements were almost exclusively served by commercial, proprietary databases. Soon after the launch of the AWS Relational Database Service (RDS) customers gave us feedback that they would love to migrate to RDS. Yet, what they desired more, was a reality that unshackled them from the high-cost, punitive licensing schemes, which came with proprietary databases.
They would love to migrate to an open-source style database like MySQL or PostgreSQL, if such a database could meet the enterprise-grade reliability and performance these high-scale applications required.
We decided to use our inventive powers to design and build a new database engine that would give database systems such as MySQL and PostgreSQL reliability and performance at scale. Meaning, at a level that could serve even the most demanding OLTP applications. It gave us the opportunity to invent a new database architecture that would address to needs of modern cloud-scale applications, departing from the traditional approaches that had their roots in databases of the nineties. That database engine is now known as “Amazon Aurora” and launched in 2014 for MySQL, and in 2016 for PostgreSQL.
Amazon Aurora has become the fastest-growing service in the history of AWS and frequently is the target of migration from on-premise proprietary databases.
In a paper published this week at SIGMOD'17, the Amazon Aurora team presents the design considerations for the new database engine and how they addressed them. From the abstract:
Amazon Aurora is a relational database service for OLTP workloads offered as part of Amazon Web Services (AWS). In this paper, we describe the architecture of Aurora and the design considerations leading to that architecture. We believe the central constraint in high throughput data processing has moved from compute and storage to the network. Aurora brings a novel architecture to the relational database to address this constraint, most notably by pushing redo processing to a multi-tenant scaleout storage service, purpose-built for Aurora. We describe how doing so not only reduces network traffic, but also allows for fast crash recovery, failovers to replicas without loss of data, and fault-tolerant, self-healing storage. We then describe how Aurora achieves consensus on durable state across numerous storage nodes using an efficient asynchronous scheme, avoiding expensive and chatty recovery protocols. Finally, having operated Aurora as a production service for over 18 months, we share lessons we have learned from our customers on what modern cloud applications expect from their database tier.
I hope you will enjoy this weekend’s reading, as it contain many gems about modern database design.
“Amazon Aurora: Design Considerations for HighThroughput Cloud-Native Relational Databases”, Alexandre Verbitski, Anurag Gupta, Debanjan Saha, Murali Brahmadesam, Kamal Gupta, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvili, Xiaofeng Bao, in SIGMOD ‘17 Proceedings of the 2017 ACM International Conference on Management of Data, Pages 1041-1052 May 14 – 19, 2017, Chicago, IL, USA.