Amazon Redshift and Designing for Security
It’s been a few months since I last wrote about Amazon Redshift and I thought I’d update you on some of the things we are hearing from customers. Since we launched, we’ve been adding over a hundred customers a week and are well over a thousand today. That’s pretty stunning. As far as I know, it’s unprecedented for this space. We’ve enabled our customers to save tens of millions of dollars in up front capital expenses by using Amazon Redshift.
It’s clear that Amazon Redshift’s message of price, performance and simplicity has resonated with our customers. That’s no surprise – these are core principles for every AWS service. But when we launched Amazon Redshift, a number of people asked me, “Aren’t data warehouses enterprise products? Do you really do enterprise? How do you handle availability, security, and integration?” My first reaction to that was, “Wait, doesn’t everybody care about these things? These aren’t enterprise-specific.” But, even if we accept that framing, we don’t have to limit ourselves to the enterprise. A lot of the power of AWS comes from the fact that we can invest in expertise in these sorts of areas and spread the benefits across all our customers. I’ve talked about performance and availability in Amazon Redshift before. This time, let’s take a look at how Amazon Redshift secures your data. I suspect it’s a lot more than what most people are doing on premise today. This is especially timely since Amazon Redshift has just been included in our SOC1 and SOC2 compliance reports.
Amazon Redshift starts with the security foundation underlying all AWS services. There are physical controls for datacenter access. Machines are wiped before they are provisioned. Physical media is destroyed before leaving our facilities. Drivers, BIOS, and NICs are protected. Access by our staff is monitored, logged and audited.
As a managed service, Amazon Redshift builds on this foundation by automatically configuring multiple firewalls, known as security groups, to control access to customer data warehouse clusters. Customers can explicitly set up ingress and egress rules or place their SQL endpoint inside their own VPC, isolating it from the rest of the AWS cloud. For multi-node clusters, the nodes storing customer data are isolated in their own security group, preventing direct access by the customer or the rest of the AWS network. Customers can require SSL for their own accesses to their cluster while the AWS operations to monitor and manage their cluster are always secured by SSL.
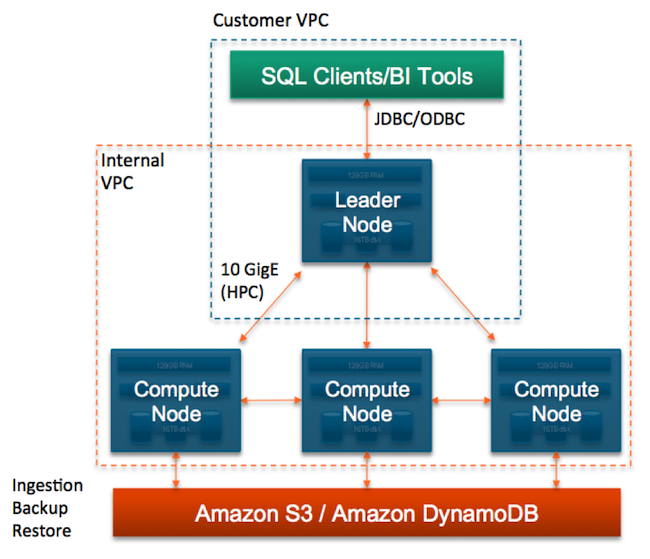
Amazon Redshift can also be set up to encrypt all data at rest using hardware-accelerated AES-256. All data includes all data blocks, system metadata, partial results from queries and backups stored in S3. Each data block gets its own unique randomly generated key. These keys are further encrypted with a randomly generated cluster-specific key that is encrypted and stored off-cluster, outside the AWS network, and only kept in-memory on the cluster itself. By using unique keys per-block and per-cluster, Amazon Redshift dramatically reduces the cost of key rotation and helps prevent unauthorized splicing of data from different blocks or clusters. We plan to support customer-managed hardware security modules (HSM) by further encrypting the cluster key, using Amazon CloudHSM or an on-premise HSM environment.
I always tell developers that they should obsess not only on the things that our customers ask for but also on the things they just expect. Chief amongst those is security. Every day, we need to come in and work hard to maintain the trust our customers have placed in us. I’m delighted to see how much work the Amazon Redshift team put into this area out of the gate.